抓包 Claude Code:system prompt、tools 与 skills 的分层设计(二)
发布时间:
接上文。上一篇拆解了 system 的三 block 结构、user message 作为 runtime injection 容器、启动上下文从 4 万降到 26.8K 的优化过程,以及 using-superpowers 的 bootstrapping 设计和 system-reminder 的真正角色。这篇继续分析 skills、tools、Skill tool、cache_control 和五层分工总结。
skills
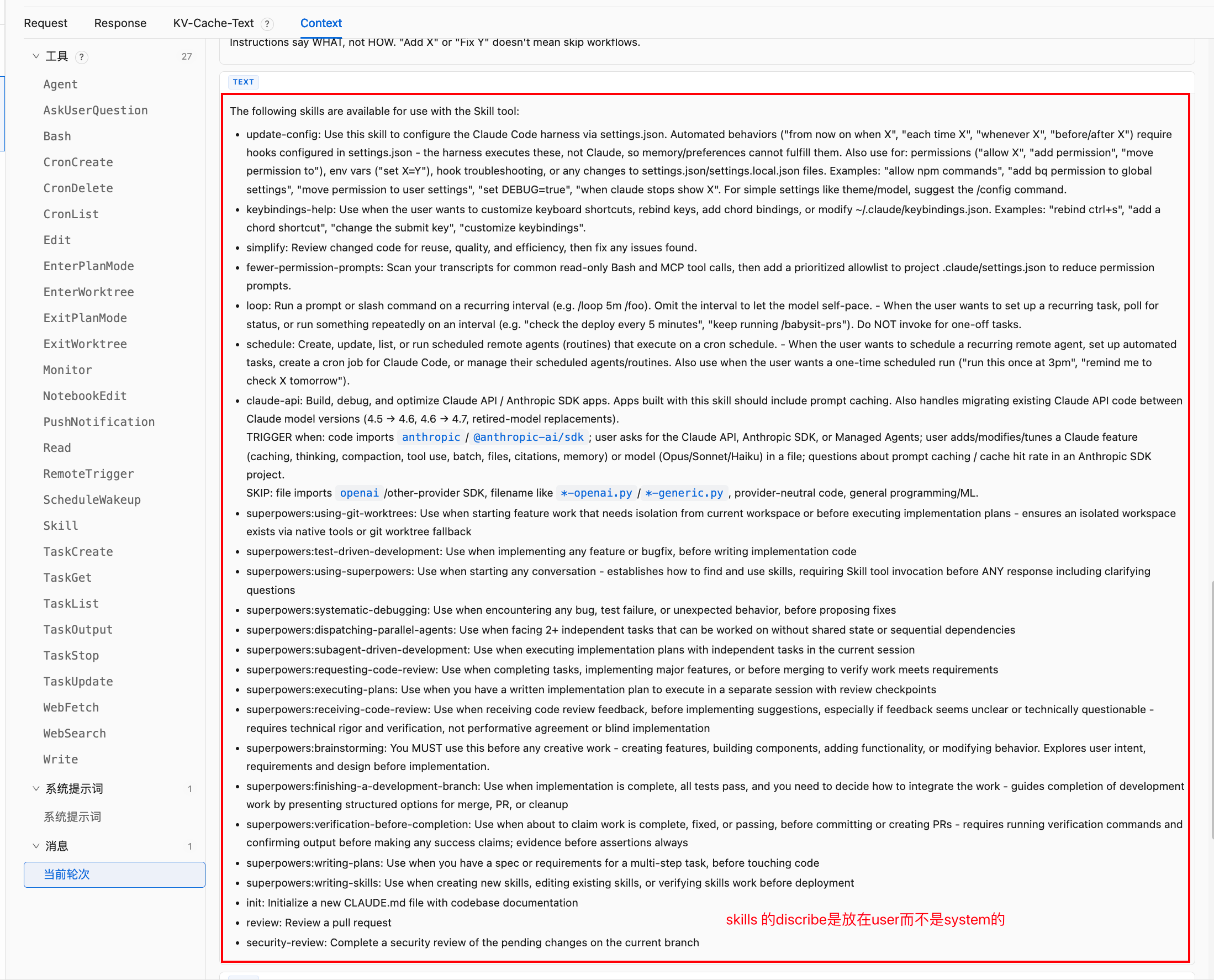
之前我记得 skills 是放在系统提示词,现在放在了 user input。改位置了。。。这个基于什么考虑的呢?可能靠后能记住?
tools
Claude Code 的 tools 字段里有一批自带工具,一共 26 个。比如 Agent、AskUserQuestion、Bash、CronCreate、CronDelete、CronList、Edit、EnterPlanMode、EnterWorktree、ExitPlanMode、ExitWorktree、Monitor、NotebookEdit、PushNotification、Read、RemoteTrigger、ScheduleWakeup、Skill、TaskCreate、TaskGet、TaskList、TaskOutput、TaskStop、TaskUpdate、WebFetch、WebSearch。
这个 tools 就不说了,不是新技术, tools 必须常驻,每次上下文带入。模型每轮都需要知道当前能调用哪些动作接口,以及每个接口的参数结构。tools 的问题也很明显:它们是固定成本。哪怕用户只是说”你好”,这些 tool definitions 仍然需要出现在请求的动作空间里。即使本轮不会用到 Cron、Monitor、TaskOutput、RemoteTrigger,这些 schema 也仍然是模型可见工具集合的一部分。
当然,实际成本不能只看 input token。因为 tools schema 高度稳定,同一个会话里基本不变,prefix cache / KV cache 可以显著摊薄重复计算成本。但 cache 只能缓解计算成本,不能完全消除两个问题:第一,tools schema 仍然占上下文预算;第二,工具越多,动作空间越大,模型选择工具的分布也越复杂。
所以,不是什么东西都应该做成 tool。如果把所有 skills 也做成 top-level tools,每个 skill 都写 description、parameters 和 JSON Schema,tools 字段会迅速膨胀。更糟的是,skills 通常是用户环境动态决定的:不同项目、不同插件、不同机器都有不同 skills 集合。把这些动态策略全部塞进常驻协议层,会污染动作空间,也会增加固定上下文成本。
这就是 Claude Code 没有把每个 skill 都建模成一个 tool 的原因。它只保留一个 Skill tool,具体 skill 不常驻为 tool,而是走二级加载。
Skill tool :context materialization API
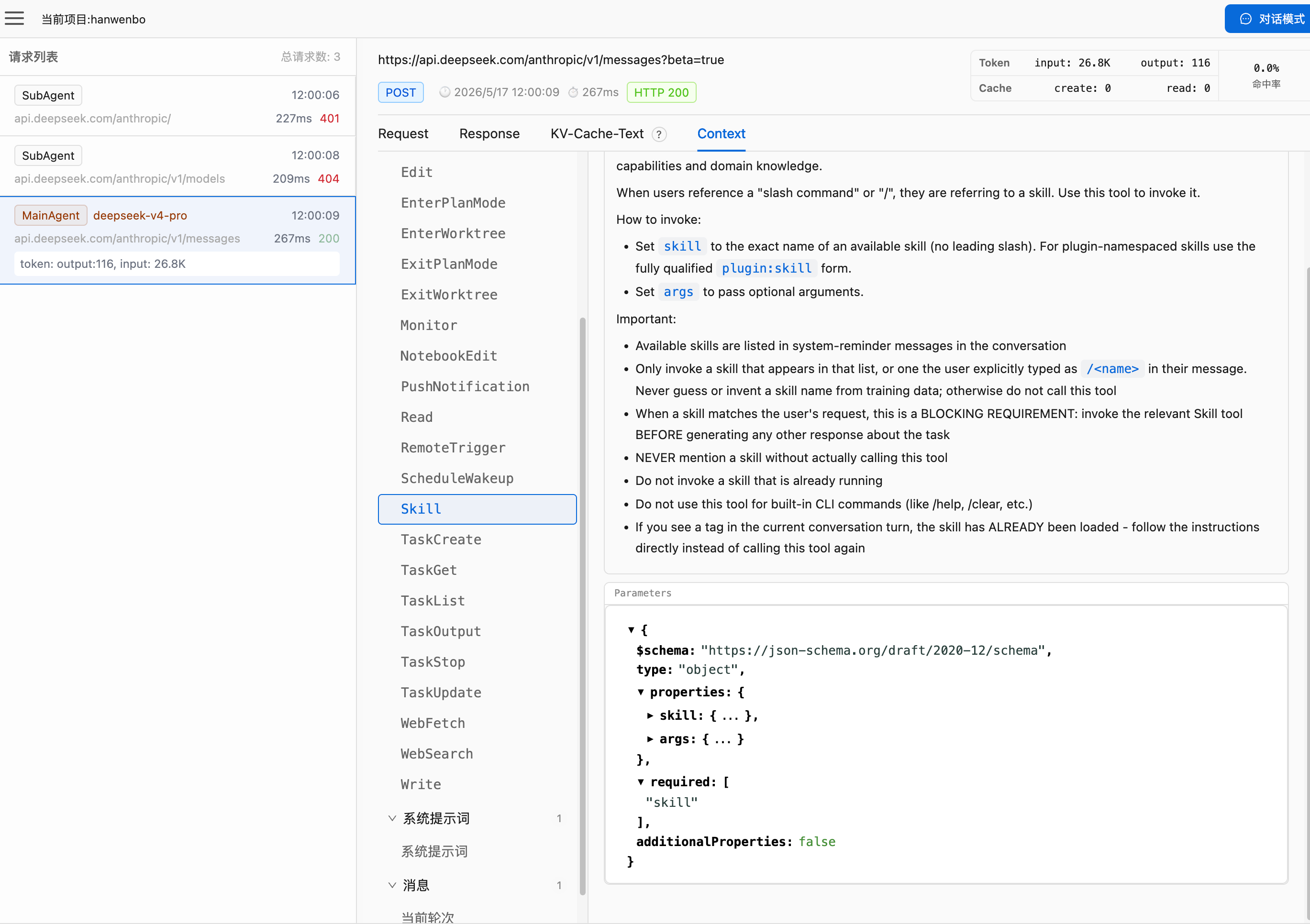
tools 里有一个 Skill。Skill tool 本身更像一个 context materialization API。它不直接执行业务动作,而是触发 harness 去磁盘读取某个 skill 的 SKILL.md,再把完整内容注入后续上下文。流程大概是:模型看到 user message 里的 skills registry,判断某个 skill 可能相关,调用 Skill tool 并传入 skill 名字;harness 读取对应 SKILL.md,把 skill 全文作为新上下文注入;模型再按 skill 里的流程继续执行。
这比 RAG 更轻,也比全量 prompt 更省。它不需要每轮都做复杂检索,也不需要把所有策略全文塞进去。它把召回责任部分交给模型:模型看到索引后,自己决定是否加载。代价也在这里:如果模型没意识到该用 skill,skill 就不会进入上下文。所以 skills 机制的核心 trade-off 是:优点是省 token、可扩展、适合动态插件、适合长尾策略;缺点是依赖模型主动调用,召回不稳定,约束力弱。
cache_control :上下文块有缓存语义
这次完整 input 里可以看到 cache_control 出现在不同位置。例如,system 里的身份声明 block:
{
"text": "You are Claude Code, Anthropic's official CLI for Claude.",
"cache_control": {
"type": "ephemeral"
}
}
用户真实输入 block:
{
"text": "你好",
"cache_control": {
"type": "ephemeral"
}
}
主 system instruction block 也带了:
"cache_control": {}
这里不展开推断具体缓存实现,因为不同厂商、不同版本的 cache control 语义可能会变。但有一点是明确的:Claude Code 不是把上下文当成无结构字符串来发,而是在 block 级别携带 cache 相关元信息。这对 Agent runtime 很关键。不同上下文块的缓存价值完全不同:billing / version metadata 低频变化;identity 极稳定;main system instruction 相对稳定;using-superpowers 随插件版本变化;skills registry 随本机 skills 集合变化;currentDate 每天变化;user input 每轮变化;tool results 高动态。如果这些内容被拼成一段纯文本,缓存边界就很粗。如果它们被拆成多个 content block,并且部分 block 带 cache control,runtime 就可以更精细地管理哪些内容适合复用,哪些内容应该快速失效,哪些内容只能属于当前 turn。所以,cache_control 的存在说明 Claude Code 的上下文设计已经进入了 block-level cache management,而不是单纯 prompt 拼接。
最终送进模型的不是一段 prompt,而是一个装配结果。这个装配结果同时包含 system-level rules、runtime metadata、developer instructions、memory policy、environment snapshot、available actions、available strategies、session facts、user task 和 cache hints。
这就是为什么我现在更倾向于把 Claude Code 理解成一个 Agent runtime,而不是一个”带 tools 的聊天壳”。它的核心复杂度不只在模型本身,而在 harness 如何管理上下文生命周期。
system prompt、tools、skills、reminders、cache 的五层分工
第一,system block 是基础宪法加 runtime metadata。system 里放的是全局稳定规则、身份、环境、memory、上下文管理、安全边界等。但这次抓包也说明,system 自身不是单一文本,而是多个 block,可以同时包含 metadata、identity 和 main instruction。
第二,tools 是结构化动作空间。tools 定义模型能调用哪些外部动作接口,以及每个接口的参数 schema。tools 是常驻的,固定成本高,但约束强。
第三,system-reminder 是 message-layer runtime injection。<system-reminder> 位于 user message 中,但不是用户真实输入。它承担 runtime 注入功能:启动策略、skills 索引、当前日期等。
第四,skills 是延迟物化的策略库。skills 不是 action primitives,而是 policy fragments。普通 skills 先以 name + description 的形式进入 registry,需要时通过 Skill tool 加载完整内容。
第五,cache_control 是 block-level 缓存提示。cache_control 说明上下文不是纯文本,而是带元信息的 block。不同 block 可以有不同缓存生命周期,这对降低长期交互成本非常关键。
哪些内容应该常驻,哪些内容应该按需加载,哪些内容应该作为 tool schema,哪些内容应该作为 user-side reminder,哪些内容应该有缓存边界,哪些规则必须进 harness,而不能只靠自然语言。一个成熟的 Agent runtime,不应该把所有东西都塞进 system prompt。那样短期简单,长期一定会膨胀。更合理的方式是做上下文分层:稳定规则放 system,真实动作放 tools,动态策略放 skills,运行时事实放 reminders,高动态任务内容放最后,硬约束放 harness,缓存边界按 block 管理。
它让我们看到一个工业级 Agent CLI 正在怎么组织上下文,而不是停留在”写一个很长的 prompt”。如果自己设计 Agent 框架,我不会从”写 system prompt”开始,而会先设计 context lifecycle。第一类是 hard constraints,比如权限、安全策略、不可绕过的审批流程。这些不应该只写在 prompt 里,而应该进 harness、router、validator 或 policy engine。第二类是 action primitives,比如 Bash、Read、Edit、Search、Browser、DatabaseQuery。这些应该做成 tool schema,数量要克制,参数要稳定,description 要短而准。第三类是 policy fragments,比如 debugging workflow、TDD、code review checklist、产品分析方法。这些应该做成 skills / playbooks,先暴露索引,再按需加载全文。第四类是 bootstrap policy,比如”如何使用 skills”、”是否必须先规划”、”何时调用 subagent”。这类内容如果影响整个 runtime 的启动行为,可以作为 session-start injection,但必须控制体积。第五类是 session context,比如当前日期、当前项目、当前分支、当前工作目录、模型版本。这些应该由 runtime 注入,但要分 block,不要糊成一坨。第六类是 task context,比如用户当前输入、错误日志、diff、检索结果。这些高度动态,应该尽量靠后,避免破坏稳定前缀缓存。第七类是 memory。memory 很容易失控,应该有明确读写策略、生命周期和索引机制,而不是把所有历史偏好都塞进 prompt。第八类是 cache policy。哪些 block 稳定,哪些 block 半稳定,哪些 block 每轮变化,必须在设计时就考虑。否则上下文越堆越长,cache 命中也会越来越差。