记录:用 AI 替代人工搭建、调试 Dify 工作流的实现
发布时间:
在使用 Dify 搭建早期,我们团队陷入了典型的低代码陷阱:拖拽节点的低门槛,掩盖了维护阶段的高成本。由于缺乏自动化测试手段,每次调整 Prompt 或逻辑分支,都需要人工做大量单点验证。这种“单点调试、线性回归”的模式,最后会落在两个致命问题上:
- 不可观测性:错误定位靠猜。日志当然能看,但你很难用它回答“到底从哪个节点开始变味”。
- 回归恐惧:没人敢轻易动核心链路。你不知道会不会引发其他效应,只能祈祷别炸。
以前的调试方式很原始:我在页面里跑一个样例,等几分钟拿到结果,再去日志里把每个节点点开,看它到底吐了什么。找到了异常节点,还得在提示词里手改,或者改代码节点,再回到页面重新跑。单样例都累,想看整体准确率更是灾难:三五个用例就是三五次等待、三五次翻日志、三五次手工统计 TP/FP/FN。更难受的是,你很难形成“改一次就安心”的节奏,因为上线前的回归检查也得照这套流程再来一遍。我想起来之前那种反复改工作流,会让人怀疑自己到底是在做 AI,还是在做手工活。
为了摆脱这种“不可控”的焦虑,我决定把“代码工程”的思维重新注入到工作流里:不再把它当成一个只能在网页里点的东西,而是当成一个可以版本化、可回放、能回归的系统。后来团队里一位老大哥(感恩(´ᴗ`ʃƪ)建哥)给我开了个窍:他会把 Dify 导出的 YAML 交给 ChatGPT Pro 先审一遍,后来是给 codex,哪里变量名不一致、哪里分支没覆盖、哪里输出结构不稳,模型能指出一堆问题,再给一版修改稿。因为啥吧,AI 不止能“跑出结果”,它还能参与维护流程。 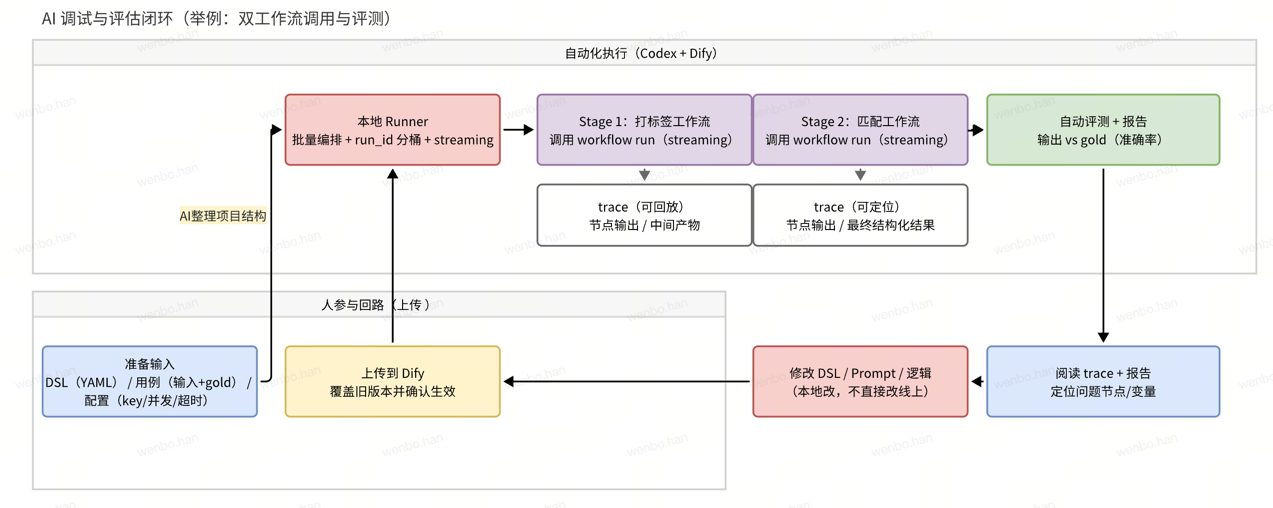 我顺着这个思路,把它落成一套本地的“工作流测试台”:它接收 YAML、用例和 key,走接口去跑工作流,并把流式输出落到文件里。每个 case 都会生成一份 trace:从 start 输入到关键节点的中间产物,再到最终输出,整个过程可回放。因为一次运行常常要 300 到 500 秒,我让脚本定时打心跳,必要时还能打印节点级进度,这样你不会盯着终端发呆,也不会猜“到底跑没跑完”。当你把过程抓住之后,很多问题会突然变简单:是某个节点丢字段了,还是某段 prompt 把结构写歪了,一眼就能看出来。
我顺着这个思路,把它落成一套本地的“工作流测试台”:它接收 YAML、用例和 key,走接口去跑工作流,并把流式输出落到文件里。每个 case 都会生成一份 trace:从 start 输入到关键节点的中间产物,再到最终输出,整个过程可回放。因为一次运行常常要 300 到 500 秒,我让脚本定时打心跳,必要时还能打印节点级进度,这样你不会盯着终端发呆,也不会猜“到底跑没跑完”。当你把过程抓住之后,很多问题会突然变简单:是某个节点丢字段了,还是某段 prompt 把结构写歪了,一眼就能看出来。
为了把这件事做成“闭环”,最后做的其实很朴素:把工作流当代码,把样例当测试,把日志变成 trace,把结果变成指标。整个流程可以概括成几步:
- 导出 DSL(YAML)并纳入版本管理,能 diff、能回滚。
- 固化一组用例:输入样例 + 金标准(gold),并写清来源和版本。
- 本地批量调用 workflow run(streaming),把每个节点的输入输出落盘,注意不能是总体的输入和结果,按
run_id分桶保存。再次强调,记录每个 node 的输出,这样输出完毕后,就能看到整个的过程,而不是只能看到结果,不知道是其中哪个步骤出了问题。 - 自动对比金标准,算出每个 case 的 Precision/Recall/F1,有的是只需要计算准确率,生成汇总报告。
- 读 trace 定位问题节点,修改 DSL 后由人工上传到 Dify,确认生效,再跑下一轮回归。
有了 trace 和报告,AI 才真正能“替代人工”去做那些重复、枯燥却又必须做对的事。它可以先跑完一批用例,再把每个异常 case 里最可疑的节点拎出来,告诉你输出从哪一行开始偏;甚至直接给出一版更稳的提示词或代码片段。人做的事情反而更清晰:决定测评口径,决定这次修改是否值得上线上,然后为线上负责。
当然,也不是一上来就顺利。我踩过最大的坑是金标准和输入根本不是同一套数据,指标会莫名其妙地低,直到把来源和版本对齐才恢复正常。自动化之前,先把对照组守住。因为一旦 gold 不干净,你会把“自我验证”当成“回归测试”,指标再漂亮也不行啊。
目前这套,它把工作流从“可用但脆弱”拉回到“可测试、可追责”的轨道。以前真的真的怕改工作流,因为改完也说不清影响范围,是否对之前所有的有正面的影响。
现在最起码知道改动会被用例集拦住,会做全部的样例测试,会被 trace 指到具体节点。目前 codex帮我排查、帮我守住质量底线。鼓掌!