GPUDirect RDMA 直接绕开 CPU 和主机内存
今天看为什么公司的h20 使用 vLLM 跑 DeepSeek 的时候,比 sglang 慢,引入了另一个兴趣点。我去翻了下 vLLM 文档,看到一段“Enable GPUDirect RDMA”。意思是:如果网卡支持 RDMA,网卡可以直接读写 GPU 的显存(VRAM),中间不必绕 CPU 和主机内存那一圈。我顺着这个点去查了下资料:本质上是走 PCIe 的 peer-to-peer 通道,把 NIC 和 GPU 放到一个“直通车”上,减少内存拷贝与 CPU 介入。这个机制在文档里写得很清楚,甚至还强调了前提条件(比如设备要在同一个 PCIe root complex 下等)。
这个图用 openai 画的:
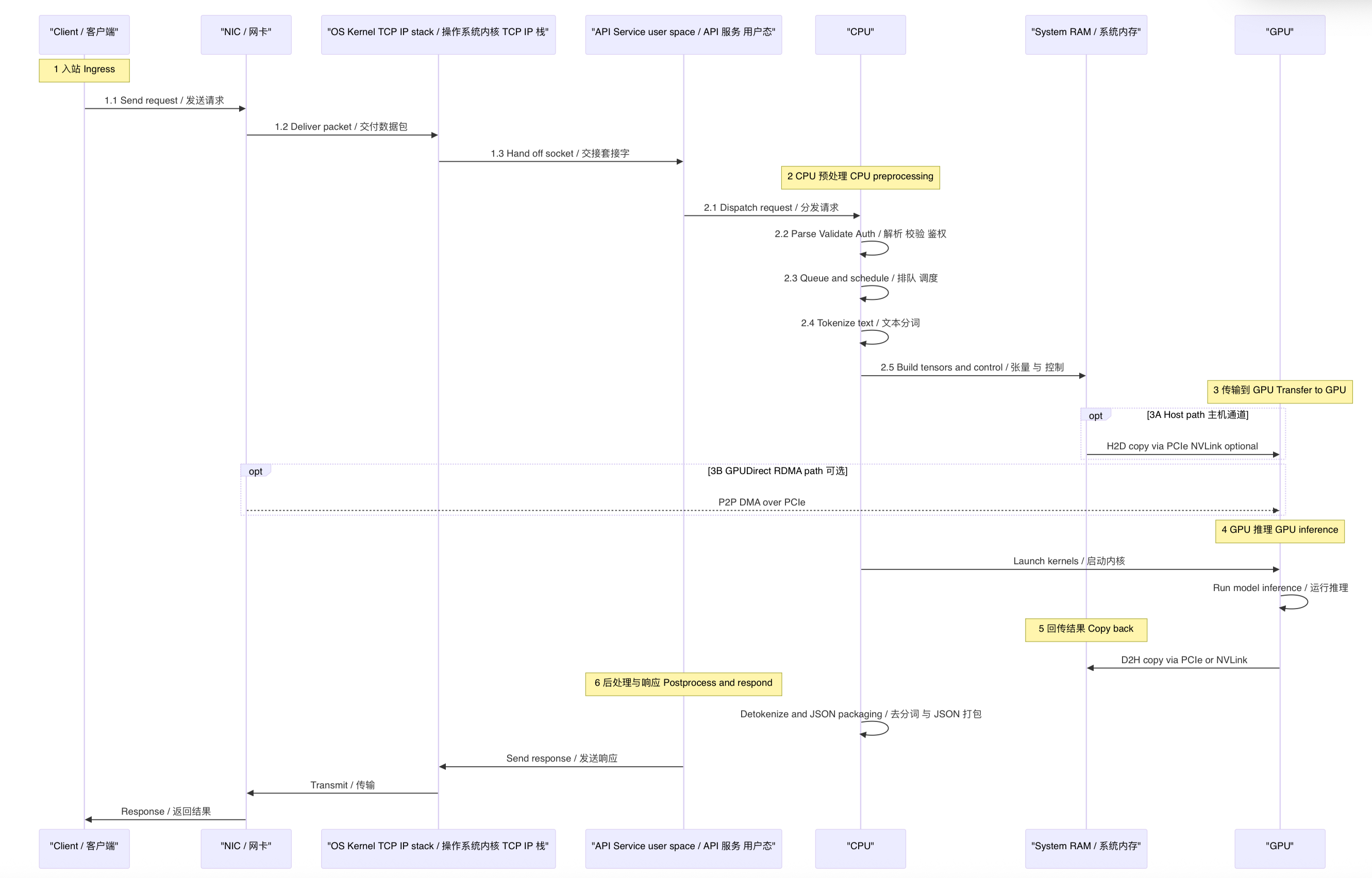
CPU 做了什么
因为一次 LLM 请求进来,其实 CPU 并没有“闲着”。把链路摊开看:
从网卡收包、内核协议栈、TLS/HTTP 解析、鉴权、排队调度,到最关键的分词(tokenization)和张量打包,这一串都发生在 CPU 和系统内存里。
GPU 真正开始干活,是把整理好的张量从 RAM 搬进 VRAM,发起 kernel 之后;
推理跑完,再把结果搬回主机,CPU 还要做去分词、采样整形、打包 JSON、打日志。
这就是为什么很多人盯着“GPU 利用率不高”时,会发现单请求延迟里,CPU 占了不小一块,尤其输入长、批次小、或者上了比较重的服务端逻辑(鉴权、路由、监控)时更明显。分布式场景里,如果做了张量并行或管道并行,节点间还要频繁交换激活和 KV 缓存碎片。
GPUDirect RDMA 到底改了哪几步
GPUDirect RDMA 想优化的,正是这条链路里“网络 ⇄ GPU”这段最贵的搬运:传统做法是 NIC 把数据先放到主机内存,CPU 参与一次或多次拷贝,再 H2D 复制进 VRAM;而启用 GPUDirect RDMA 后,NIC 可以直接 DMA 到 GPU 显存,省掉 RAM 中转、减少一次 H2D 拷贝、也降低 CPU 的中断和上下文切换。结果就是端到端延迟更低、吞吐更高,P99 更稳,特别是在多机多卡、通信量很大的并行推理里收益更大(小规模两台机器各一张卡的场景,收益会小一些,这点在社区讨论里也有人实测过)。
需要提醒两件事。
第一,GPUDirect RDMA 不是“用 NVLink 把 NIC 和 GPU 连起来”,它走的是 PCIe 的直通路径;NVLink 主要是 GPU↔GPU(以及少数平台的 CPU↔GPU)高速互联,这是两条不同的路。
第二,要真正用起来,软硬件都得配齐:RDMA 能力的 NIC(常见是 ConnectX 家族或等价设备)、正确的驱动与内核模块(例如 nvidia-peermem)、合适的 IOMMU 与拓扑设置,以及上层框架的配置开关。vLLM 文档里有“如何启用”的章节,平台文档也会强调“同一 root complex”这类前提,不满足就可能跑不起来或达不到预期带宽。
这项技术解决和未解决的
解决的:
- 少一次从主机内存到显存的大拷贝。
- 少一堆 CPU 参与的中断、内存触碰与上下文切换。
- 网络一侧更贴近 GPU,跨机并行时更能顶住大流量的激活/KV 交换。
没解决的:
- 分词、排队调度、结果解码与 JSON 打包,这些前后处理依然主要在 CPU。
- 模型计算还是在 GPU;如果瓶颈在算力(比如小显存导致分块、或 FP8/INT8 没吃满),RDMA 不是灵丹妙药。