few-shot 最佳实践指南
在过去的几个月里,我总是习惯于把Few-shot放在系统提示词里。但是我经过使用LangGraph,Dify和其他平台的一些实践,我慢慢地发现,放在QA问答对的几个shot,总是会比放在系统提示词里效果会更好。后来我又开始借鉴在twitterRohan的推文使用llamaindex搭建的动态提示词系统。这并不是熟能生巧,这方面的论文和Medium的文章给了我很大启发,然后我在LangChain的官方博客发现了一篇总结得非常好的文章,我一直拖到今天元旦终于闲下来才下定决心写一个翻译稿件。
以下内容包含两个实验,尝试了以下5种few-shot少样本技术。
对比实验1介绍
尝试了以下5种少样本技术(按预期它们的表现递增排序):
zero-shot
仅向模型输入基本system prompt系统提示词和Question问题
<|im_start|>system
任务:根据给定的句子,生成与其相反的句子。<|im_end|>
<|im_start|>user
REAL QUESTION: 请生成“太阳从西边升起”的相反句子。<|im_end|>
<|im_start|>assistant
REAL ANSWER: 太阳从东边升起。<|im_end|>
few-shot-static-msgs, k=3
三个固定的few-shot,在系统提示词和最终的问题之间。也就是这样的:
<|im_start|>system
任务:根据给定的句子,生成与其相反的句子。<|im_end|>
# 示例 1
<|im_start|>user
EXAMPLE 1: QUESTION: 我喜欢夏天。<|im_end|>
<|im_start|>assistant
EXAMPLE 1: ANSWER: 我不喜欢夏天。<|im_end|>
# 示例 2
<|im_start|>user
EXAMPLE 2: QUESTION: 天空是蓝色的。<|im_end|>
<|im_start|>assistant
EXAMPLE 2: ANSWER: 天空不是蓝色的。<|im_end|>
# 示例 3
<|im_start|>user
EXAMPLE 3: QUESTION: 我喜欢吃辣的食物。<|im_end|>
<|im_start|>assistant
EXAMPLE 3: ANSWER: 我不喜欢吃辣的食物。<|im_end|>
<|im_start|>user
REAL QUESTION: 我喜欢猫。<|im_end|>
<|im_start|>assistant
few-shot-dynamic-msgs, k=3
三个动态的few-shot,在系统提示词和最终的问题之间。动态的few-shot可以通过与使用嵌入模型计算与问题的相关程度,向量数据库从向量库里召回3个最相关的问答对的方式来实现。
<|im_start|>system
任务:根据给定的句子,生成与其相反的句子。<|im_end|>
# 动态示例 1
<|im_start|>user
DYNAMIC EXAMPLE 1: QUESTION: 今天下雨了。<|im_end|>
<|im_start|>assistant
DYNAMIC EXAMPLE 1: ANSWER: 今天没下雨。<|im_end|>
# 动态示例 2
<|im_start|>user
DYNAMIC EXAMPLE 2: QUESTION: 我喜欢甜的食物。<|im_end|>
<|im_start|>assistant
DYNAMIC EXAMPLE 2: ANSWER: 我不喜欢甜的食物。<|im_end|>
# 动态示例 3
<|im_start|>user
DYNAMIC EXAMPLE 3: QUESTION: 秋天很凉爽。<|im_end|>
<|im_start|>assistant
DYNAMIC EXAMPLE 3: ANSWER: 秋天不凉爽。<|im_end|>
<|im_start|>user
REAL QUESTION: 冬天很冷。<|im_end|>
<|im_start|>assistant
few-shot-str, k=13
将所有 13 个few-shot 组合为一个长字符串,并将其附加到系统提示中。
<|im_start|>system
任务:根据给定的句子,生成与其相反的句子。
EXAMPLE 1: QUESTION: 我喜欢苹果。
EXAMPLE 1: ANSWER: 我不喜欢苹果。
EXAMPLE 2: QUESTION: 今天是晴天。
EXAMPLE 2: ANSWER: 今天不是晴天。
...
EXAMPLE 13: QUESTION: 我喜欢阅读。
EXAMPLE 13: ANSWER: 我不喜欢阅读。<|im_end|>
<|im_start|>user
REAL QUESTION: 你喜欢跑步吗?<|im_end|>
<|im_start|>assistant
few-shot-msgs, k=13
所有 13 个少样本示例都作为系统提示和人类问题之间的一条消息列表传入。
<|im_start|>system
任务:根据给定的句子,生成与其相反的句子。<|im_end|>
# 示例 1
<|im_start|>user
EXAMPLE 1: QUESTION: 我喜欢夏天。<|im_end|>
<|im_start|>assistant
EXAMPLE 1: ANSWER: 我不喜欢夏天。<|im_end|>
# 示例 2
<|im_start|>user
EXAMPLE 2: QUESTION: 天空是蓝色的。<|im_end|>
<|im_start|>assistant
EXAMPLE 2: ANSWER: 天空不是蓝色的。<|im_end|>
...
# 示例 13
<|im_start|>user
EXAMPLE 13: QUESTION: 我喜欢跑步。<|im_end|>
<|im_start|>assistant
EXAMPLE 13: ANSWER: 我不喜欢跑步。<|im_end|>
<|im_start|>user
REAL QUESTION: 我喜欢猫。<|im_end|>
<|im_start|>assistant
对比实验1结果
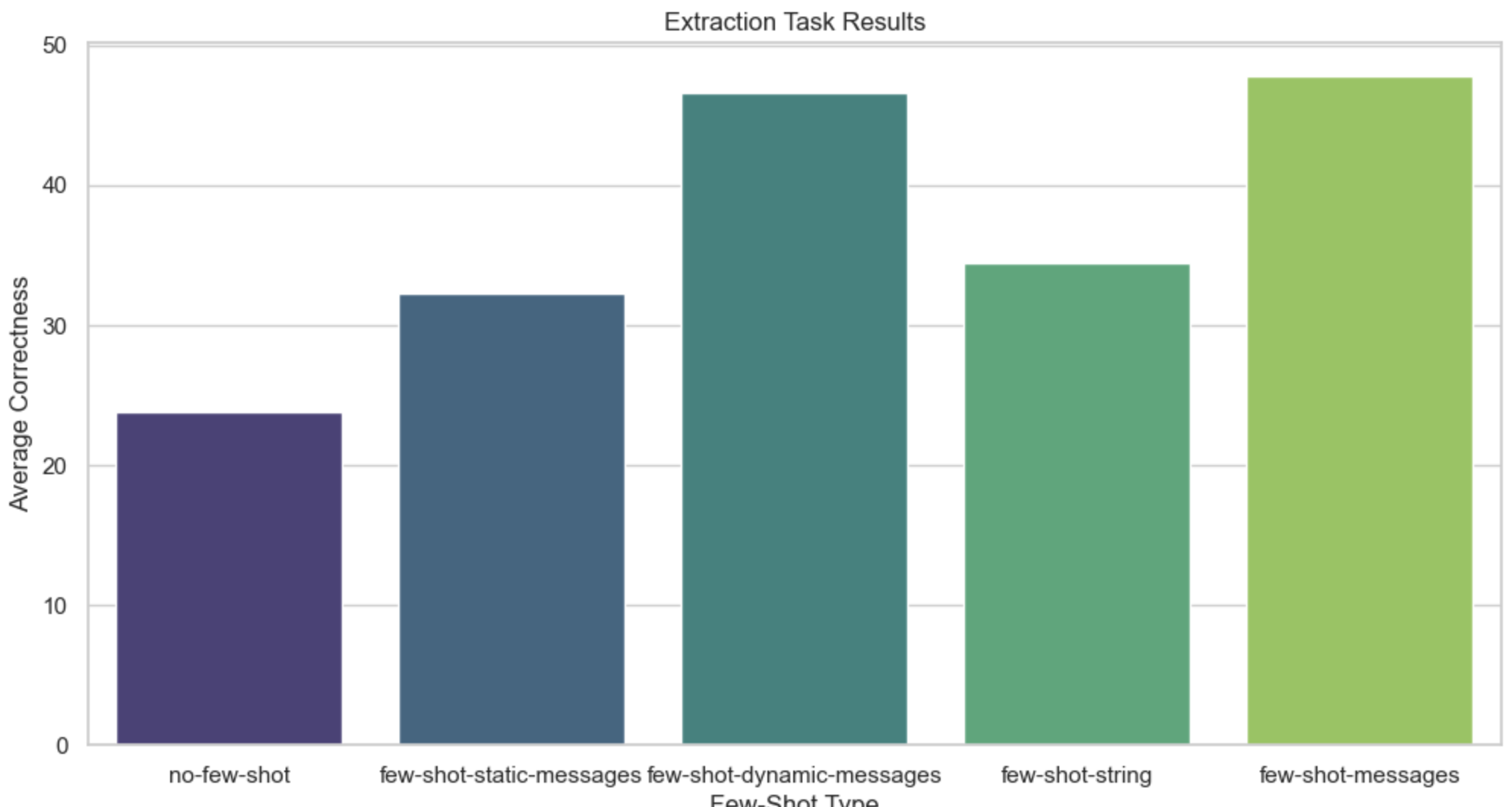
结果按模型拆分:
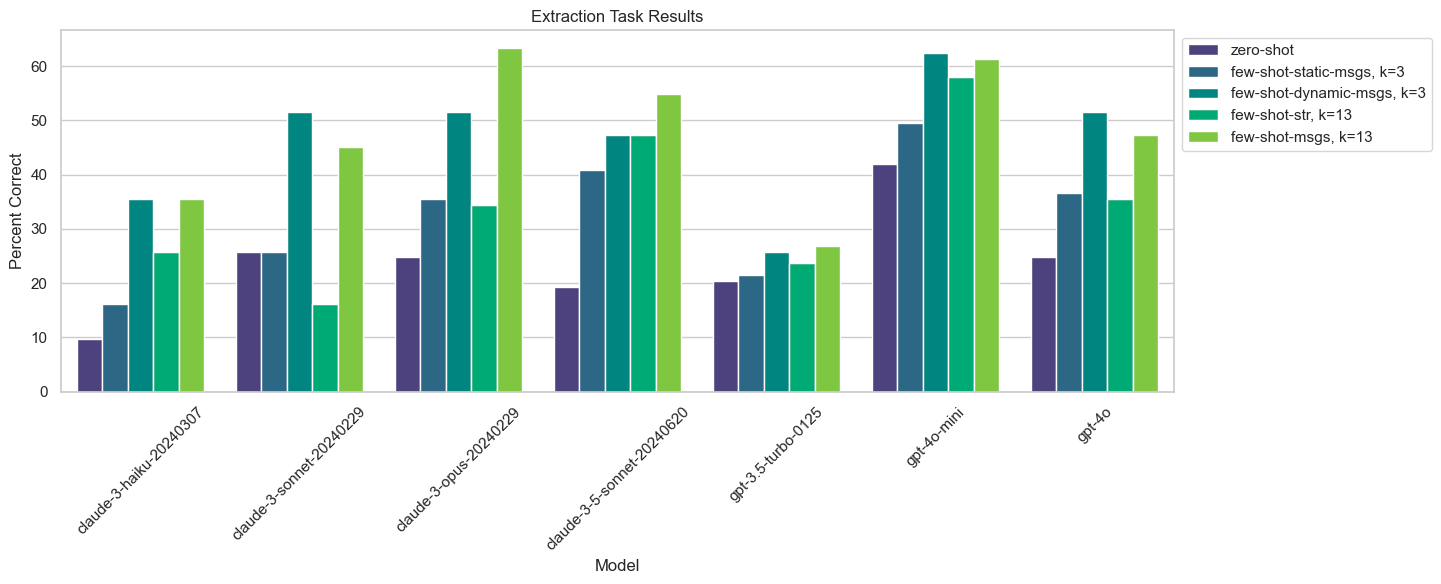
观察结果,我们可以看到的结论:
任何类型的 Few-shotting 都能在整体上带来相当显著的提升。Claude 3 Sonnet 的表现从零样本的 16%提升到使用 3 个语义相似的示例消息后的 52%。
使用 3 个语义相似的示例作为消息进行 Few-shotting 比 3 个静态示例表现更好,通常与所有 13 个示例相当或更好。
少量使用消息进行 Few-shotting 通常比使用字符串表现更好。
Claude模型在少样本学习方面比 GPT 模型提升更大。
对比实验2介绍
zero-shot
仅向模型提供了基本系统提示和问题。
few-shot-str, k=3
将三个固定示例转换成一个长字符串,并将其附加到系统提示中。消息使用 ChatML 语法格式化。
few-shot-msgs, k=3
将三个固定示例作为系统提示和人类问题之间的消息列表传递。
few-shot-str, k=9
将所有九个少样本示例转换为一个长字符串,并将其附加到系统提示中。
few-shot-msgs, k=9
所有九个少样本示例都作为系统提示和人类问题之间的一条消息列表传入。
对比实验2结论
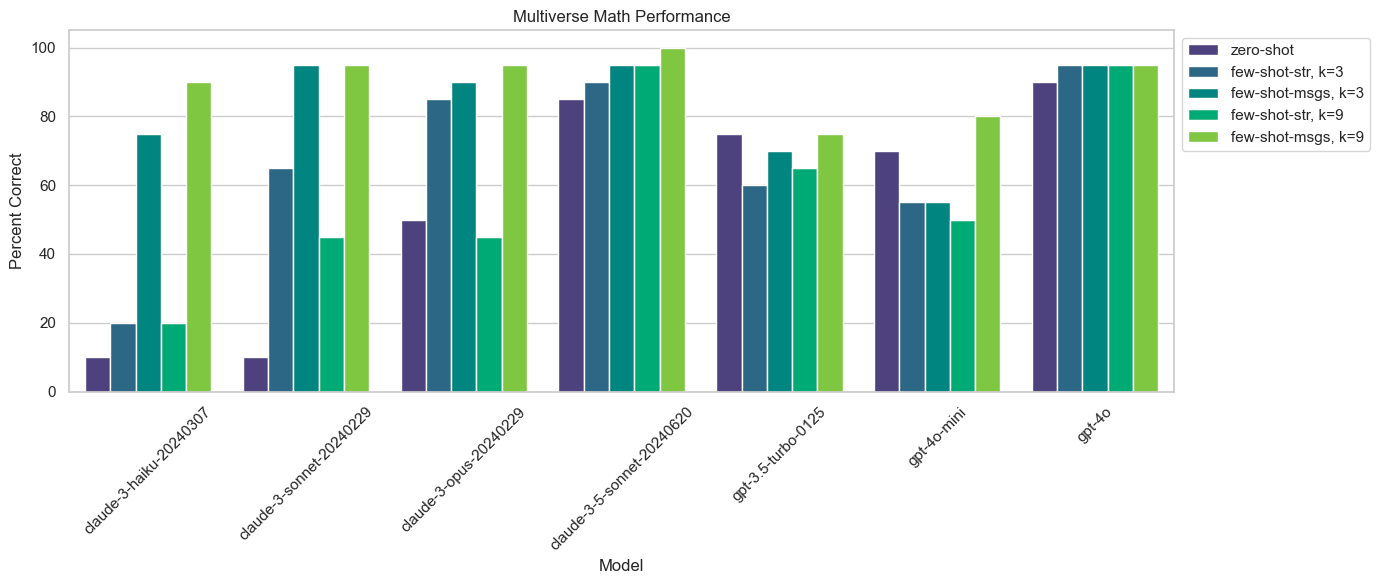
观察结果,我们可以看到的结论:
- Few-shotting少样本学习,包括所有 9 个示例作为消息,几乎总是优于zero-shotting零样本学习,并且通常表现最佳。
- Claude 3 模型在少量示例消息中进行少样本学习时改进显著。Claude 3 Haiku 在没有任何示例的情况下实现了 11%的整体正确率,但在仅有 3 个示例消息的情况下达到了 75%。这与其他所有零样本性能一样好,除了 Claude 3.5 Sonnet 和 GPT-4o。
- Claude 3 模型在将示例格式化为字符串并添加到系统消息时改进很小或根本没有。注意:这可能是因为示例的格式化方式,因为我们使用 ChatML 语法而不是 XML。
- OpenAI 模型在少样本学习方面看到的效果要小得多,如果没有效果的话。
- 使用3个示例(即少量示例)作为训练数据的性能与使用全部9个示例的性能是相似的。这通常表明,随着你增加少量示例的数量,每增加一个示例所带来的性能提升可能会逐渐减少,这种现象被称为“递减回报”。换句话说,增加更多的示例并不会显著提高模型的性能,可能在某个点之后,性能的提升会趋于平缓,甚至不再有显著的改进。